In today’s fast-paced digital age, businesses increasingly rely on mobile apps to operate and generate profits. Unfortunately, the need to regularly check website status or program performance remains an issue even among the most prominent players with all the resources and expertise they have access to. Here are three essential methods you can utilize to ensure minimal downtime and deliver a consistently reliable customer experience.
Implement a best-of-breed monitoring stack
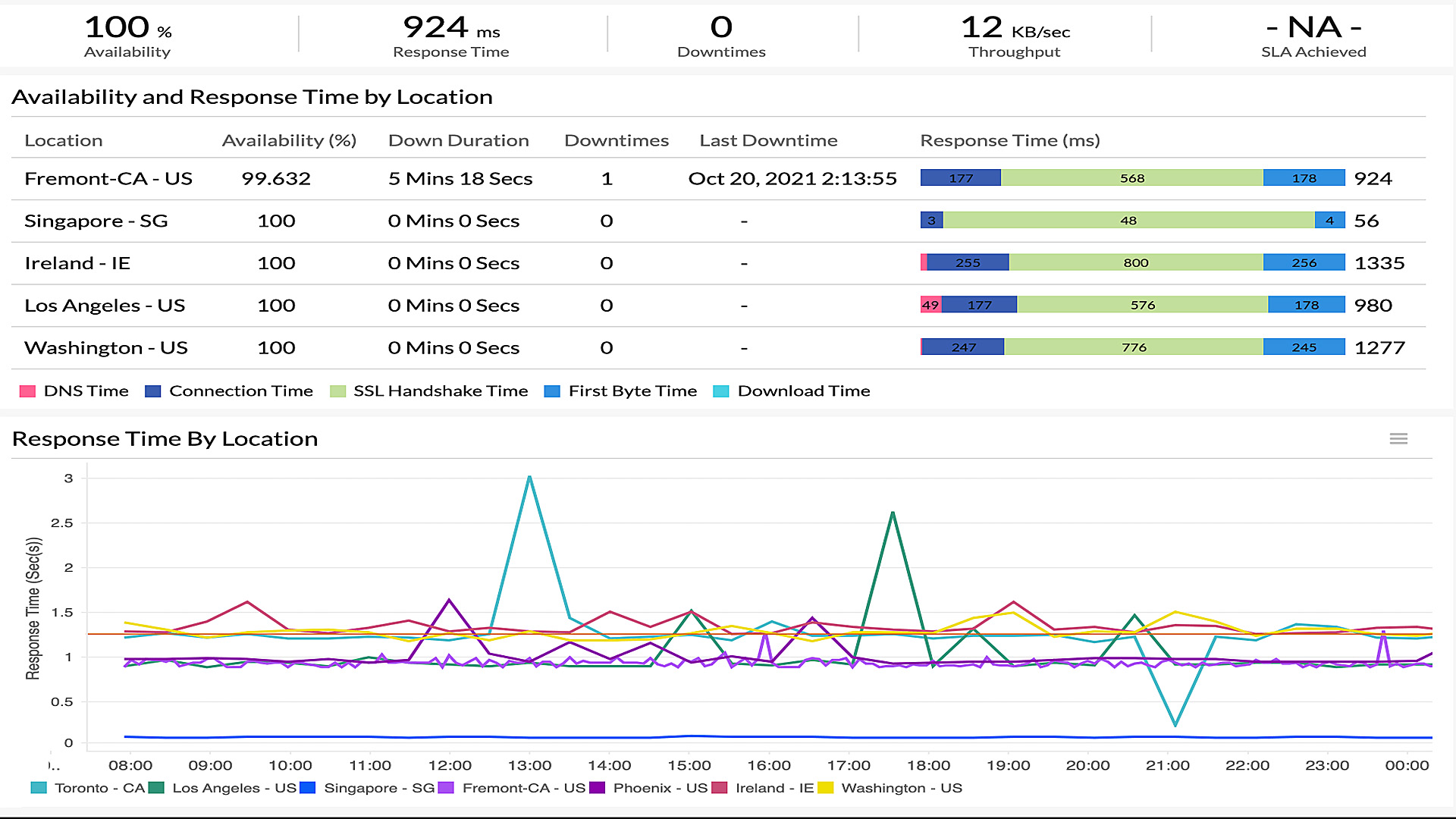
Businesses can effectively monitor their health and take action if needed by utilizing the highest quality monitoring tool on each application stack layer. This innovative best-of-breed approach has swiftly gained traction in the IT industry, rapidly replacing outdated monolithic monitoring architectures. Systems monitoring, application monitoring, web and user tracking platforms, logging systems, and error reporting are all improved with this method. For example, it can be helpful if you want to know about the Cox internet outage.
Advanced infrastructure monitoring systems let businesses watch out for areas of vulnerability and address any issues before downtime occurs. The process includes tallying and documenting the downtimes’ related data, such as application performance metrics and system resource utilization. By continuously measuring these alert rules against current metrics, you can detect when it’s best to take action from this metric collection analysis.
Use distributed architecture for applications
Microservices architecture is a method of crafting applications in which each service carries out one business function and stands alone. This way, if one service experiences an issue or downtime, it won’t affect the rest of your application. When utilizing this model for creating software, you can be confident that there will not be any disruption to your entire system.
When constructing a complex distributed architecture, certain fundamentals must be considered and addressed with care:
- Service-level agreement.
- Horizontal vs. vertical scaling.
- Data durability.
Eliminate single points of failure
High availability is typically associated with developing a reliable infrastructure built out of redundant and resilient systems. At its essence, high availability seeks to remove any single points of failure that could lead to system downtime. To ensure this level of continuity, load balancers are typically inserted between clients and servers to spread out traffic to eliminate such risks. High availability enables businesses and organizations around the globe to operate more efficiently while minimizing the potential disruption or loss due to their technical architecture.
For your applications to operate quickly and optimally, you must balance their workloads across numerous servers. Distributing processing power between two or more systems is known as load balancing, and it can help guarantee that requests are processed timely – even when one node becomes unavailable unexpectedly.
System downtime can be costly for any business, with IDC and AppDynamics research finding that it could cost up to $100,000 per hour. It might not always be possible to stop system failures from taking place altogether. Still, by introducing proactive preventive measures, the organization will have more time to identify and fix issues before they become too disruptive.